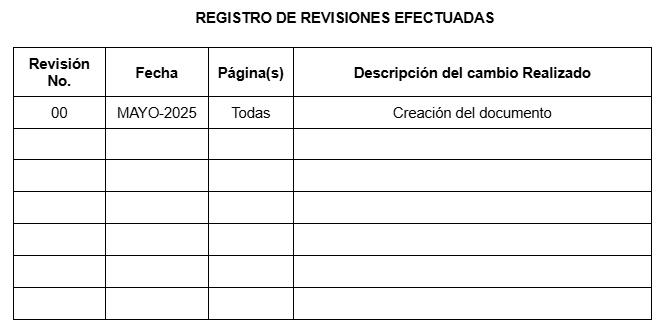
PROTOCOLO DE EMERGENCIA
PROTOCOLO DE EMERGENCIA PARA ATENCIÓN DE FALLAS DE RED
OBJETIVO
Establecer un procedimiento claro y eficiente para la detección, diagnóstico, contención, resolución y comunicación de fallas que afecten a un número significativo de nuestros clientes o a la infraestructura crítica de nuestra red de fibra óptica.
ALCANCE
Este protocolo aplica a todas las fallas que resulten en la pérdida total o parcial del servicio de internet a través de un nodo de acceso FTTH o de la red en General, incluyendo problemas de energía, hardware, fibra óptica y configuración lógica, impactando directamente en la satisfacción del cliente y la competitividad de la empresa.
RESPONSABILIDADES Y REVISIONES RELACIONADAS CON EL DOCUMENTO
PERSONAL INVOLUCRADO GESTIÓN Y ATENCIÓN DE FALLAS
Primer Nivel de Atención (N1): Personal de soporte técnico.
Segundo Nivel de Atención (N2 - Gerencia de Planta Interna): Técnicos especializados en planta interna, responsables de la infraestructura física, incluyendo equipos y fibra óptica.
Tercer Nivel de Atención (N3 - Gerencia de Redes): Ingenieros de redes responsables de la configuración lógica de los equipos y la arquitectura de la red.
PROCEDIMIENTO A IMPLEMENTAR
Fase 1: Detección y Alarma
Monitoreo Proactivo (24/7):
Implementación de un sistema de monitoreo continuo de la red que alerte sobre caídas de nodos, altos niveles de latencia, pérdida de paquetes, y otros indicadores de falla.
Configuración de umbrales de alarma para identificar posibles fallas masivas en etapas tempranas.
Alertas automáticas vía correo electrónico, SMS y/o aplicaciones de mensajería al equipo de guardia.
Tener un sistema de monitoreo en sistealarmas que estará a cargo de un operador, el mismo se encargará de hacer seguimiento y enviar las alertas (llamadas o mensajes) al personal a través del grupo de Telegram.
Reporte de Usuarios:
Los usuarios pueden reportar la falta de servicio a través de los canales de atención al cliente (telefónico, correo electrónico, etc.).
Implementación de un sistema de gestión de tickets que registre automáticamente los reportes, priorizando aquellos que indiquen una afectación a múltiples usuarios en una misma zona.
Reporte de Personal interno:
El personal de la empresa que esté en calle o que cuente con servicio de cortesía puede reportar si detecta o si visualiza alguna incidencia que pueda afectar la red de nuestros clientes (cajas o reservas caídas, cortes de cable principales, fallas de equipos centrales).
Confirmación Inicial (N1):
El personal de N1 recibe la alerta o el reporte del usuario, todos los responsables pertenecen a N1 ya que estarán agregados al sistema de notificación vía Telegram, deberán asegurarse de que todos los responsables estén informados y dependiendo de la naturaleza de la falla se pongan en marcha las actividades necesarias para la restauración del nodo y estar atentos en caso de que se necesita su apoyo presencial en la solución de la incidencia.
Se verifica la caída del nodo a través de las herramientas de monitoreo.
Realiza pruebas básicas de conectividad remota al nodo (si es posible).
Abre un ticket de incidencia con la siguiente información:
Número de ticket único.
Nodo de acceso afectado (identificador único).
Hora de inicio de la falla.
Descripción del problema (según la alerta o el reporte).
Impacto estimado (número de usuarios afectados, servicios impactados).
Información de contacto del usuario reportante (si aplica).
Nivel de urgencia (crítico).
Fase 2: Diagnóstico y Escalación
Activación del Equipo de Emergencia:
Designación de un equipo de guardia de fines de semana que incluya personal clave de redes, soporte técnico y comunicaciones. Operaciones deberá realizar planificación de personal que estará de guardia semanalmente.
Activación del equipo a través de los canales de alerta definidos al detectarse una posible falla masiva. (Whatsapp, grupo de Extra o Soporte Técnico donde esté el personal correspondiente)
El equipo de guardia realiza una verificación inicial de las alarmas del NMS y los reportes de clientes para confirmar la magnitud y ubicación aproximada de la falla.
Acceso remoto a los equipos de red para realizar diagnósticos básicos (ping, traceroute, revisión de logs).
Comunicación con el personal técnico en campo si la falla parece localizada.
Determinación de la Magnitud y Prioridad:
Evaluación del número de clientes afectados, la criticidad de la infraestructura impactada y el posible impacto en servicios esenciales (si aplica).
Clasificación de la falla según su gravedad (e.g., Nivel 1 - Crítico, Nivel 2 - Mayor, Nivel 3 - Significativo).
Diagnóstico Remoto Inicial (N1):
Verifica el estado de los equipos del nodo (routers, switches, OLT) a través de las herramientas de gestión.
Revisa alarmas específicas generadas por los equipos.
Verifica el estado de los enlaces troncales hacia el nodo.
Si se identifica un problema lógico evidente (e.g., pérdida de configuración reportada por el sistema), se intenta una resolución remota siguiendo los procedimientos documentados.
- Escalación (N1 a N2 o N3):
- Si el problema no se resuelve remotamente o se sospecha de una falla física o de energía, el ticket se escala inmediatamente al nivel correspondiente:
- Sospecha de falla física de equipos (router, switch, OLT): Se escala a la Gerencia de Redes (N3)
- Sospecha de falla en la alimentación eléctrica (local o proveedor): Se escala a la Gerencia de Planta Interna (N2).
- Sospecha de falla en la fibra óptica (enlaces de subida o distribución): Se escala a la Gerencia de Planta Interna (N2).
- Sospecha de problema de configuración lógica compleja: Se escala a la Gerencia de Redes (N3).
- En la escalación, se debe adjuntar toda la información recopilada en el ticket.
- Diagnóstico en Sitio (N2 - Planta Interna):
- El equipo de Planta Interna se desplaza al sitio del nodo afectado.
- Falla de Energía:
- Verifica el estado del suministro eléctrico del proveedor
- Inspecciona el funcionamiento del sistema UPS e inversores.
- Realiza pruebas de continuidad y voltaje.
- Si es un problema del proveedor, contacta inmediatamente a la empresa de energía y realiza seguimiento.
- Si es un problema del UPS/inversor, intenta la reparación o sustitución inmediata.
- Falla Física de Equipos:
- Inspecciona visualmente los equipos (luces de estado, conexiones).
- Intenta reiniciar los equipos de forma controlada.
- Si el reinicio no soluciona el problema, procede con la sustitución del equipo defectuoso por un equipo de respaldo, siguiendo los procedimientos documentados.
- Falla de Fibra Óptica:
- Realiza pruebas de continuidad y potencia óptica en los enlaces de fibra (troncal y distribución).
- Identifica la ubicación del corte o la atenuación excesiva.
- Coordina la reparación de la fibra óptica (empalme, sustitución de tramo) por personal capacitado.
- Diagnóstico Lógico Avanzado (N3 - Gerencia de Redes):
El equipo de la Gerencia de Redes accede remotamente a los equipos del nodo (si es posible) o trabaja en coordinación con el equipo de Planta Interna presente en el sitio.
Revisa la configuración de los routers, switches y OLT.
Verifica el estado de las interfaces, VLANs, protocolos de enrutamiento, y políticas de calidad de servicio (QoS).
Analiza los logs de los equipos para identificar errores o eventos inusuales.
Realiza pruebas de ping, traceroute y otras herramientas de diagnóstico de red.
Aplica las correcciones de configuración necesarias siguiendo los procedimientos de gestión de cambios.
Fase 3: Resolución y Restauración del Servicio
Implementación de la Solución:
Planta Interna: Realiza la reparación o sustitución de hardware defectuoso, la reparación de la fibra óptica o la restauración del suministro eléctrico alterno.
Gerencia de Redes: Aplica las correcciones de configuración necesarias en los equipos.
Pruebas de Verificación:
Una vez implementada la solución, se realizan pruebas exhaustivas para verificar la correcta restauración del servicio.
Se verifica la conectividad a nivel de equipo y a nivel de usuario (si es posible).
Se monitorean los indicadores clave de rendimiento (KPIs) del nodo para asegurar la estabilidad del servicio.
Comunicación:
Desarrollar plantillas de comunicación pre-aprobadas para diferentes tipos de fallas masivas, lo que permitirá agilizar la emisión de información a los clientes.
Se informa al personal de N1 sobre la resolución de la falla.
El personal de N1 actualiza el ticket de incidencia con la descripción de la solución implementada y la hora de restauración del servicio.
Se comunica a los usuarios afectados sobre la restauración del servicio a través de los canales definidos, enviar (SMS, correo electrónico, redes sociales, etc.).
Se debe mantener en todo una comunicación fluida y constante entre el equipo de emergencia, el personal técnico en campo, el equipo de atención al cliente y la gerencia.
Utilización de canales de comunicación dedicados (e.g., grupos de WhatsApp, entre otros) para compartir información y coordinar acciones.
Realizar actualizaciones periódicas sobre el estado de la falla, el progreso de la reparación y comunicar el tiempo estimado de restablecimiento del servicio.
Fase 4: Cierre y Análisis Post-Incidente
Cierre del Ticket: Una vez confirmado el restablecimiento del servicio y la satisfacción del usuario (si aplica), el ticket de incidencia se cierra.
Análisis Post-Incidente:
Se convoca a una reunión con representantes de las gerencias de Redes y Planta Interna para analizar la causa raíz de la falla.
Se identifican las lecciones aprendidas y las áreas de mejora en los procesos, la infraestructura o la capacitación del personal.
Se elabora un informe post-incidente detallado con las conclusiones y las recomendaciones.
Monitoreo continuo de la red para asegurar la estabilidad y prevenir la recurrencia de la falla.
Se toman las medidas necesarias para evitar que fallas similares ocurran en el futuro. Esto puede incluir la actualización de equipos, la mejora de los procedimientos de mantenimiento, la redundancia de la infraestructura, etc.
PROTOCOLO PARA LA REPARACIÓN DE CORTES EN CABLE DE FIBRA ÓPTICA ADSS
- Sección de Herramientas:
OTDR: Para realizar el estudio de reflectometría desde el nodo.
Bobina de lanzamiento: Permite que el OTDR estabilice su medición antes de alcanzar el tramo de fibra bajo prueba.
Patch cord: SC/APC a SC/APC, SC/UPC a SC/UPC)
Cable ADSS: El lugar varía dependiendo del tipo de cable de partido, pueden ser de los siguientes tipo H-6/H-8/H12/H24/H48.
Mangas de empalme: Para proteger y reforzar el punto de fusión donde se unen dos fibras ópticas.
Adicional: Peladora Longitudinal de fibra óptica, Cortadora de precisión (Cleaver), Sangradora de tubing, Striper para fibra óptica, Fusionadora de fibra óptica, Alcohol isopropílico y toallas de limpieza para fibra, Guantes antiestáticos, Equipos de comunicación (radios, teléfonos), Elementos de seguridad personal (casco, gafas, guantes). En caso de que la falla sea nocturna, lámparas led de emergencia inalámbricas.
Sección de Acción y Ejecución:
1.1. Realizar la prueba de reflectometría (OTDR) desde el nodo para identificar la ubicación aproximada del corte.
1.2. Analizar la traza del OTDR para determinar la distancia a la falla y las características del evento (corte abrupto, alta reflectancia, etc.).
1.3. Registrar los resultados del OTDR (captura de pantalla de la traza, distancia estimada).
2.1. Desplazarse al punto medio estimado de la falla (caja de empalme o manga más cercana).
2.2. Realizar una nueva prueba de OTDR desde este punto en ambas direcciones (si es posible) para acotar la ubicación del corte.
2.3. Inspeccionar visualmente la ruta del cable en la zona sospechosa en busca de daños evidentes (rotura, caída de ramas, vandalismo, etc.).
2.4. Si la falla no es visible, considerar el uso de un localizador visual de fallas (VFL) si la rotura no es severa y permite el escape de luz.
3.2. Solicitar y retirar del almacén el cable ADSS del tipo y longitud requeridos, junto con los preformados, flejes, pasantes y cualquier otro material necesario para la instalación.
3.3. Planificar la logística del reemplazo, incluyendo el acceso al sitio, la seguridad del personal y del área de trabajo, y la coordinación con el equipo de apoyo (camión, ayudantes).
4.1. Ubicar y asegurar un equipo de técnico líder (Técnico A) en cada extremo del tramo a reemplazar (Extremo A y Extremo B).
4.2. El equipo de ayudantes o del camión procede a retirar el cable dañado, siguiendo los procedimientos de seguridad y las mejores prácticas para el tendido de cable ADSS.
4.3. Instalar el nuevo cable ADSS, utilizando los preformados, flejes y pasantes de acuerdo a las especificaciones técnicas y asegurando la correcta tensión del cable.
4.4. Dejar una longitud adecuada de fibra óptica en cada extremo para realizar los empalmes.
5.1. Preparar los extremos de las fibras del cable nuevo y del cable existente para el empalme (pelado, limpieza, corte con cleaver).
5.2. Realizar el empalme de las fibras utilizando la fusionadora, siguiendo las recomendaciones del fabricante.
5.3. Proteger los empalmes con las mangas termocontraíbles.
5.4. Organizar y asegurar las mangas de empalme.
5.5. Repetir los pasos 5.1 a 5.4 para el otro extremo del cable reemplazado.
6.1. Una vez realizados los empalmes se debe comunicar con el departamento de soporte técnico para la validación de la potencia de los clientes y revisar que los pon estén arribas.
6.2. Realizar pruebas de servicio (si es posible y necesario) para asegurar la correcta restauración del servicio.
7.1. Registrar detalladamente el trabajo realizado, incluyendo la ubicación exacta de la falla, la longitud del cable reemplazado, el tipo de cable, los materiales utilizados y cualquier otra observación relevante.
7.2. Documentar en el Ozmap los cambios realizados en la red con la información del cable reemplazado y los nuevos empalmes.
CONSIDERACIONES ADICIONALES
Documentación: Mantener actualizada la documentación de la red FTTH, incluyendo diagramas de la infraestructura, documentación de la configuraciones de los equipos, procedimientos de troubleshooting y contactos clave de proveedores.
Inventario: Mantener un inventario actualizado de equipos de repuesto críticos (OLTs, routers, switches, fuentes de alimentación, módulos de fibra, etc.) en ubicaciones estratégicas.
Capacitación: Implementar un programa de capacitación continua para todo el personal técnico y de soporte en la identificación, diagnóstico y resolución de fallas, así como en los procedimientos de comunicación.
Comunicación Interna: Establecer canales de comunicación claros y eficientes entre los diferentes niveles de atención y las gerencias involucradas durante la gestión de la emergencia.
Plan de Continuidad de Negocio: Este protocolo debe integrarse dentro del plan de continuidad de negocio general del ISP, considerando escenarios de fallas mayores o desastres.
Acuerdos de Nivel de Servicio (SLA): Considerar los SLAs definidos con los clientes al momento de priorizar y resolver las fallas.
Interrupciones de Energía: Dada la realidad local, es fundamental tener planes de contingencia para cortes de energía, incluyendo el uso de UPS (Uninterruptible Power Supply) y generadores eléctricos en puntos críticos de la red.
Logística: Planificar la disponibilidad de repuestos críticos y la logística para su transporte y despliegue en caso de emergencia.
Integración con Redes Sociales: Monitoreo de redes sociales para identificar picos de reportes de interrupción del servicio en áreas específicas, lo que puede complementar los datos del NMS y los reportes directos.
Análisis de Patrones Históricos: Utilizar datos históricos de fallas para identificar zonas o momentos del día más propensos a incidentes, permitiendo una vigilancia proactiva en esos períodos.
Alertas por Georreferenciación (ZONAS Y SECTORES): Implementar un sistema que correlacione las alertas del NMS y los reportes de clientes con la ubicación geográfica para identificar rápidamente la extensión de una posible falla masiva.
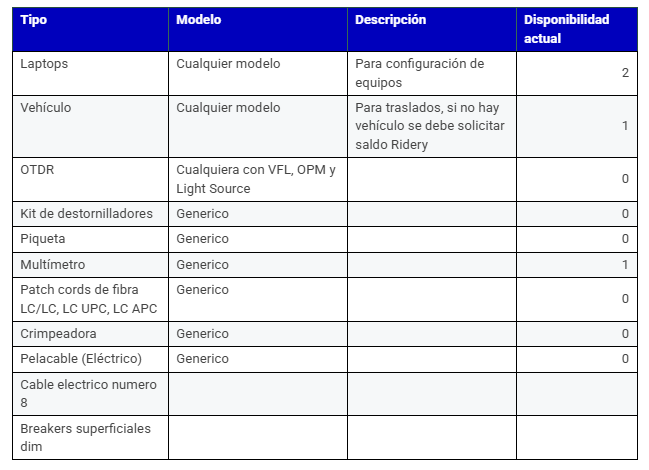
Disponibilidad de herramientas: se debe garantizar que la división de Planta interna tenga su kit de herramientas y equipos completos para poder realizar de manera oportuna las labores de reparación.
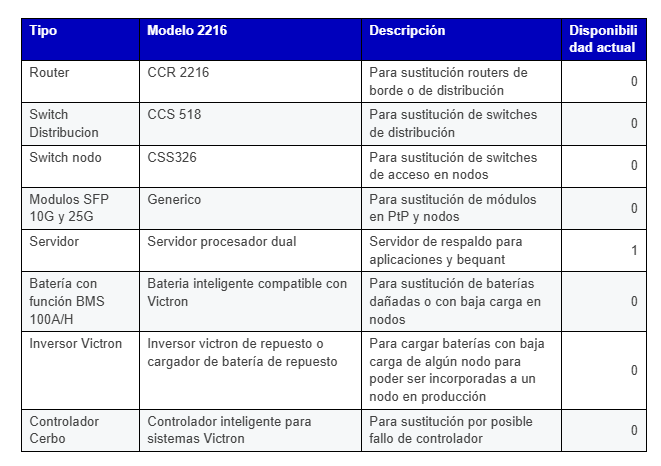
Recursos necesarios:

No hay comentarios por ahora.
para ser el primero en comentar.